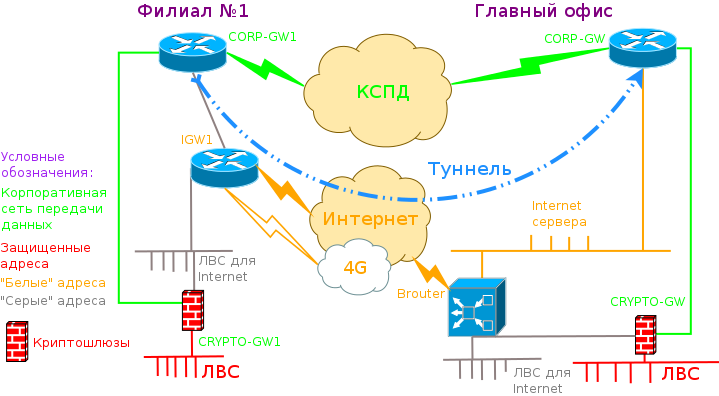
Моя предыдущая статья о совмещенном брандмауэре с маршрутизатором натолкнула на мысль, а что если броутеру не давать персональный IP вовсе? Ведь через него проходит весь трафик от внешнего маршрутизатора в локальную сеть. Пусть он поделит один публичный адрес между двумя хостами: для собственных нужд и для остальных сервисов на публичном адресе в "белой" сети. Обычно такие задачи решают заведением демилитаризованной зоны с серыми адресами. Но тогда нам необходимо убедиться, что все публичные сервисы поддерживаются на уровне протоколов пограничным маршрутизатором с сетевой трансляцией для поддержания сессий. Это и не всегда возможно, требует значительных ресурсов и появляются трудности внутри сети с доступом к соседним публичным адресам изнутри самой демилитаризованной зоны.
А у нас всё ещё сложнее:
Этой задачей я грезил много-много лет. Казалось бы, вставим в разрыв сети от провайдерского маршрутизатора и своей сети хитрый почти прозрачный мост, который будет сам поднимать туннель, проверять доступность каналов и переключать маршруты.
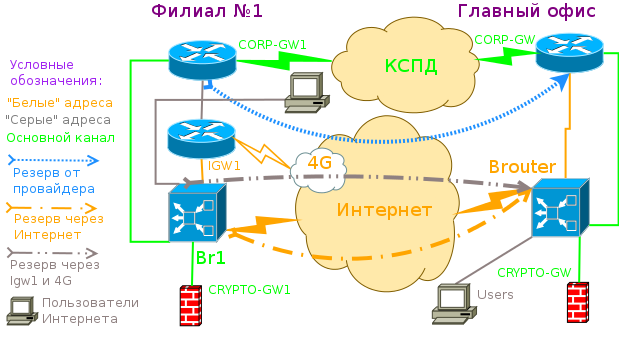
Исходя из вышеизложенного алгоритма данную задачу уже можно решить, воспользовавшись реализацией из предыдущей статьи. Скрипт по переключению каналов для корпоративной сети будет управлять режимом броутинга. Выключение моста и переход на маршрутизацию делается командой:
ebtables -t broute -A BROUTING -i eth-in -p ipv4 -j redirect --redirect-target DROP
где eth-in — интерфейс моста к шлюзу crypto-gw*
Особенность такого решения будет в том, что маршрут до удаленной стороны можно сделать сразу. Вы можете сколько угодно проверять на самих хостах Brouter* доступность удалённой стороны через туннель, это не помешает проходить пакетам по зеленому пути, так как включенный мост срабатывает ранее маршрутизации. Вот только вышеприведённое решение требует адресов как в корпоративной сети, так и в публичной сети для сервера туннелей.
Нарисуем схему сети исходя из имеющихся адресов:
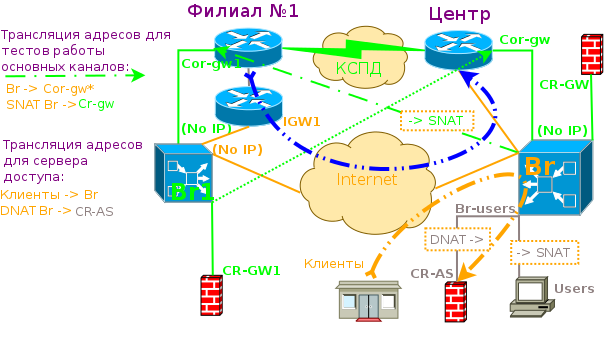
Для моего случая, свободный адрес корпоративной сети у филиала имеется, он же и будет основным адресом дополнительного хоста Br1, а для центра мы будем маскироваться под адрес CR-GW при проверке Br -> Corp-gw1.
Ох уж эта вечная проблема... Почему она вообще возникает? При обмене пакетами, если по пути встретится интерфейс, у которого максимальный размер пакетов сконфигурирован менее, чем у всех ранее пройденных, то ядро такого хоста в зависимости от флага допустимости или нет фрагментации может либо разбить пакет, если оно пожелает и флаг запрещения фрагментации DF не установлен либо должно сгенерировать ICMP пакет об превышении размера допустимых пакетов. А вот далее возникает проблема прохождения таких ответов до отправителя и правильное реагирование с уменьшением размера пакета, особенно если на той стороне пакеты инкапсулируются в туннель, который уменьшает как и любая инкапсуляция размер пакета уже сама по себе.
У уменьшения MTU есть ещё одна неприглядная сторона — это приводит к увеличению паразитного трафика, когда доля основной информации к общему трафику падает из-за увеличения доли вспомогательной информации: заголовков пакетов. Особенно это проявляется, если мы будем бороться с mtu туннелями, которые будут не информировать стороны о реальных размерах после инкапсуляции, а самовольно разбивать пакет на два и более частей, а потом последовательно их собирать на удаленной стороне, тем самым оставляя первоначальное mtu.
Что же собственно я решал? У меня была проблема с прекращением работы закрытого криптосредства после уменьшения до определенного значения mtu. Я подозреваю, что это у них произошло по следующей причине. Для борьбы с первой проблемой mtu по разрешению прохождения ответов по коррекции mtu и правильной интерпретации и вычисления корректного требуемого размера авторы скорее всего применили грязный хак: фиксировано ограничили размер пакетов через туннель. Это работает до определенного значения mtu на внешних к туннелю интерфейсах и очень трудно диагностируется в виду сжатия пакетов в примененном ими туннеле. Решение, увы, напрашивается одно — не выходить ниже определённого значения по внешнему (открытому) к туннелю пути.
Какие есть варианты по экономии mtu:
Общая идея всех туннелей, что мне попадались в следующем: не залезая во внутренние данные пакетов, все действия с ними производятся как с единым блоком данных. Пакеты могут вначале сжать для увеличения энтропии, потом зашифровать, потом даже нарезать. Как следствие, ничего хорошего в результате не получается. Сжатие пакета целиком производит небольшой выигрыш в размере: заголовок пакета бинарен, плохо поддаётся сжатию общими методами увеличения энтропии, эти бинарные данные как бы загрязняют вложенные полезные данные, которые если не зашифрованы и передают какой-либо текст, то могут быть хорошо сжаты. Хорошо сжимает заголовки VJ-компрессор. Но он имеет свои недостатки: работает только с TCP-пакетами, имеет своё состояние и кеш... Как вы уже поняли, я могу долго и нудно говорить на эту тему и пора бы уже перейти к интересной части статьи.
Моя идея по всеми силами уменьшить размер пакета после инкапсуляции состоит в следующем: давайте таки разберем заголовок вложенного IP пакета и
Так по зёрнышку в результате у меня получился выигрыш 14-16 байт для следующих опций: количество хостов не более одна сеть/24 и 1 хост/32 и хост с туннелем, протоколы только TCP/UDP/ICMP, фиксированные ttl. Для справки: размер заголовка IP+UDP — 28 байт, минимальная добавка к заголовку для внутренних целей туннелирования: 1-2 байта. Что в сумме даёт как минимум 28-14+2=12 байт, что заметно лучше, чем туннель с минимальной добавкой без ухищрений: IPIP 20 байт. А вот OpenVPN у меня требует аж 84 дополнительных байт. И в этой задаче потому он бы не подошёл.
Значение MTU вычисляется и устанавливается интерфейсу tun моей программой автоматически, согласно указанным перечислениям адресов/сетей, какие мы хотим пропускать через наш туннель, вплоть до 0/0. Это тоже может дать выигрыш, так как смысла делать туннель с разрешением пропуска всех адресов на обеих сторонах не просматривается для нашей, да и вообще для большинства задач.
После того, как у меня схема заработала стало понятно, почему такое решение, наверное, и невозможно найти в сети. На первый взгляд всё что требуется для успешной работы схемы уже изложено в алгоритмах решения выше. Но как это и обычно получается, это обманчиво. Вот смотрите. Если у нас нет адреса у машины в главной сети, то какой адрес шлюза указать рабочему хосту? Конечно, когда у нас brouter работает в режиме моста, то это не имеет ровным счётом никакого значения, так как безусловно хост будет отправлять пакеты через маршрутизатор, без учёта, какой адрес мы присвоили управляющему интерфейсу моста/коммутатора. Выключив же мост, на удивление ничего страшного не произойдёт, пакеты отправятся по интерфейсу с нулевым адресом на выходной интерфейс согласно маршрутизации по адресу назначения, ведь в самом деле, внутренние адреса интерфейсов в обычной маршрутизации значения не имеют. Но тут и возникает засада. Перед тем как отправить пакет в интерфейс в свободное плавание, необходимо узнать адрес назначения всех нижележащих протоколов, в которые будет обернута наша полезная информация. То есть ядро рабочего хоста перед отправкой пакета с данными должно узнать MAC для нашего шлюза. А если шлюз неработоспособен, потому мы и хотим перейти на запасной? Маршрутизацию то мы включим на бывшем до этого прозрачном мосте, но пакеты не получим, так как рабочий хост перед отправкой пакетов будет долго и мучительно ждать работоспособности своего шлюза по умолчанию, опрашивая его MAC. Вот мы и подошли к изюминке этой статьи. Ну а как же? Всё дело как всегда в деталях. После продолжительных размышлений, а ведь это действительно не сразу доходит, почему вот только что всё работало, а после паузы — перестало, я решил, что неверное ничего лучше, чем жестко прописать в скриптах MAC адрес нашего корпоративного шлюза, а потом применить грязноватый хак, но весьма действенный: пусть будет постоянный ответ от моста на запрос MAC шлюза. То есть работает он или нет, мост будет отвечать хостам жестко прописанным этим MAC.
ebtables -t nat -A PREROUTING -p ARP -i eth2 --arp-op Request \
--arp-ip-dst `resolv corp-gw` -j arpreply --arpreply-mac ${a}6
где ${a} — MAC у интерфейса corp-gw
Не всё так же просто и с маршрутизацией. Во-первых, ядро само прописывает маршруты для эзернет интерфейсов с IP адресом. У нас же придётся прописывать маршруты для хоста Br самостоятельно. Но и это не поможет для работы маршрутизации без указания MAC для тех шлюзов, где будет маршрутизация с несконфигуренного адреса. Интересный эффект, впрочем вполне объяснимым, также можно наблюдать, если вы укажете маршруты до удалённых сетей без указания шлюза, в надежде, что шлюз мы уже указывали ранее. Ядро это позволит сделать, но работать такой маршрут начнёт только после указания MAC для этого удаленного хоста равному MAC шлюза. Объяснение этому очень простое, так как абсолютно все IPv4 адреса попадают под "сеть" на интерфейсе у неуказанного адреса 0.0.0.0/0.0.0.0, то ядро считает, что все адреса находятся вот сразу на этом супер-глобальном эзернете и значит надо искать MAC перед тем как начать обмен с любым адресом.
Как и в прошлой статье, я и в этот раз подготовил готовый образ виртуальной машины, один для всех хостов на основе qemu и ядром Linux и моей версией busybox. Прошёл год с момента написания прошлой статьи, за это время я таки решился поменять в моей сборке (они же и в мейнстримной сборке) минимальные варианты утилит ping и ip на полноценные. Уж очень хочется провести полные тесты, воспользоваться опциями обычного варианта утилиты ping для получения пакетов разной длинны и детектирования ответных ICMP пакетов.
Как ни покажется странно, но на написание своего "OpenVPN" у меня ушло не много времени. Но секрет прост: я уже делал этот компрессор IPv4 заголовков для туннеля vtund, много лет его использовал для VPN дом-работа, но сейчас полностью переписал. Это дело обычное, когда умеешь и делаешь для себя — берем готовое, правим и понимаем, что проще написать с нуля...
На полноценную утилиту ip я возлагал надежды на проведения испытаний разных типов встроенных туннелей, но встроенные не подошли из-за проблем, описанных в главе о экономии IP адресов. Так как пакет включал в себя утилиту tc, то я очень надеюсь, что следующая статья будет о tc — управлении трафиком. Многочисленные тесты выявили ошибку портирования утилиты ebtables, присутствовавшую в предыдущей версии моего busbox, где она только появилась.
Как и в прошлый раз, создание и описание лаборатории надо начинать с упрощении схемы сети и назначении адресов, а ещё лучше и их имён на интерфейсах.
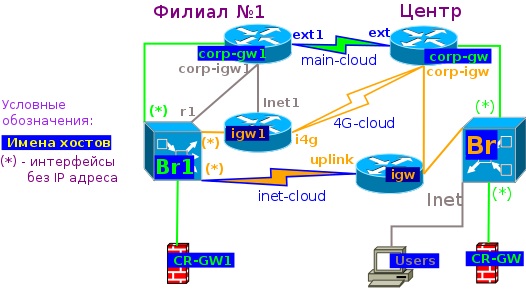
Для сетевого взаимодействия виртуальных машин пронумеруем tap интерфейсы и мосты.
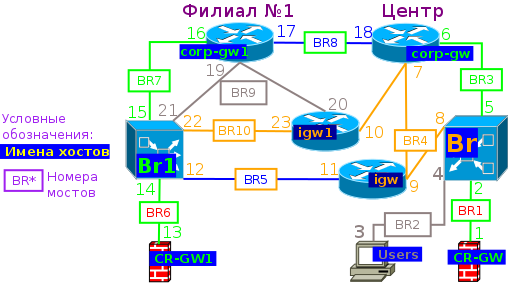
Соответственно, файлы в виртуальных машинах будут для /etc/hosts:
# For loopbacking. 127.0.0.1 localhost 10.68.0.1 cr-gw tap1 #0.0.0.0 ZERO TAP2 192.168.0.1 users tap3 192.168.0.254 inet tap4 #0.0.0.0 zero tap5 10.68.0.254 corp-gw tap6 1.1.0.3 corp-igw tap7 1.1.0.2 br tap8 1.1.0.254 igw tap9 1.1.0.100 i4g tap10 1.1.1.254 uplink tap11 #0.0.0.0 zero tap12 10.68.1.1 cr-gw1 tap13 10.68.1.2 br1 tap14 #0.0.0.0 zero tap15 10.68.1.254 corp-gw1 tap16 10.68.254.1 ext1 tap17 10.68.254.254 ext tap18 192.168.1.3 corp-igw1 tap19 192.168.1.1 inet1 tap20 192.168.1.100 r1 tap21 #0.0.0.0 zero tap22 1.1.1.1 igw1 tap23 # for fw 255.255.255.255 broadcast
где сети /etc/networks:
# loopback 127.0.0.0 cr-net 10.68.0.0 public-net 1.1.0.0 inet-net 192.168.0.0 cloud-net 10.68.254.0 cr1-net 10.68.1.0 inet1-net 192.168.1.0 inet-cloud 1.1.1.0 tunnel-net 10.0.0.0 # for fw link-local 169.254.0.0 Test-net 192.0.2.0 Unallocated 248.0.0.0 Private-172 172.16.0.0 Multicast-224 224.0.0.0 Reserved-240 240.0.0.0 # for micro tst lab tst-net 10.68.45.0
Теперь у нас виртуальных машин больше 9, потому пришлось изменить скрипт по их запуску, воспользовавшись уже полным последним байтом MAC, пусть и не прибегая к трансляции десятеричной в шестнадцатеричную систему:
#!/usr/bin/env bash
#
# Usage
#
# lab_start.sh [all] [[-]host ...]
# start hosts (all) -do not start this hosts
HOSTS="cr-gw:1 br:8:4:2:5 corp-gw:6:18:7 corp-gw1:16:17:19 br1:14:21:15:12:22 igw:9:11 cr-gw1:13 igw1:23:20:10 users:3"
. ./lab0.sh
minus2underline_set() {
local __h=${1//-/_}
eval $__h=$2
}
minus2underline_tst_non_zero() {
local h=${1//-/_}
h=${!h}
[[ -n $h && 0 -ne $h ]]
}
cut_host() {
local __out __out2 __IFS=$IFS
__out=$1=\$$3
__out2=__out2=\$$3
IFS=:
set -- $2
IFS=$__IFS
eval $__out
shift
eval $__out2
[ -z "$__out2" ]
}
declare -a nic_args
start() {
local i t r=1
echo -n start $1
nic_args=()
for((i=2;r!=0;i++)); do
cut_host t $2 $i
r=$?
nic_args+=("-net")
nic_args+=("nic,vlan=$t,model=virtio,macaddr=52-54-00-12-34-$t")
nic_args+=("-net")
nic_args+=("tap,vlan=$t,script=no,downscript=no,ifname=tap$t")
echo -n " tap$t"
done
echo
qemu-system-x86_64 -name $1 \
-boot c -m 64M -enable-kvm \
-drive file=$IMG,if=virtio,format=raw \
"${nic_args[@]}" \
-display sdl -vga vmware \
-parallel none -serial none -balloon none -localtime -daemonize
}
s=x$1
if [[ x = $s ]]; then
s=xall
fi
while [[ x != $s ]]; do
found=0
for ht in $HOSTS; do
cut_host h $ht 1
if [[ xall = $s || $s = x$h ]]; then
minus2underline_set "$h" 1
found=1
elif [[ $s = x-$h ]]; then
minus2underline_set "$h" 0
found=1
fi
done
if [ $found -eq 0 ]; then
if [[ ${s:0:2} != x- ]]; then
minus=
else
minus="-"
fi
echo "$0: "$minus"host '$1' unknown" 2>&1
exit 1
fi
shift
s=x$1
done
for ht in $HOSTS; do
cut_host h $ht 1
r=$?
if minus2underline_tst_non_zero "$h"; then
if [ $r -eq 0 ]; then
echo "Do not found tap's number for host $ht" 2>&1
exit 1
fi
start $h "$ht"
fi
done
Скрипт настройки мостов на хостовой системы логику не поменял, но, безусловно, требует новую конфигурацию, потому я его облагородил для работы со строкой конфигурации:
#!/usr/bin/env bash
BR=br
nr_br=1
. ./lab0.sh
BRIDGES="1-2 3-4 5-6 7-10 11-12 13-14 15-16 17-18 19-21 22-23"
add_int() {
ifconfig $1 down && ifconfig $1 0.0.0.0 promisc up
brctl addif $2 $1
}
br_close() {
ifconfig $1 down && brctl delbr $1
}
br_start() {
br_close $1 && brctl addbr $1
for ((I=$1; I<=$2; I++)); do
ifconfig tap$I > /dev/null 2>&1 || tunctl -t tap$I -u $USER
add_int tap$I $1
done
brctl stp $1 off && ifconfig $1 up
}
if [[ xstart == "x$1" || xclose == "x$1" ]]; then
for b in $BRIDGES; do br_$1 "$BR$((nr_br++))" ${b%-*} ${b#*-}; done
else
echo usage: $0 'start|close' >&2 && exit 1
fi
Для виртуальных машин специальных хостов Br и Br1 дополнительно вызывается скрипт под созданию мостов, теперь с помощью утилиты ip
#!/bin/sh echo Configure br$1 ip link add br$1 type bridge ip link set dev $2 master br$1 ip link set $2 up ip link set dev $3 master br$1 ip link set $3 up ip link set br$1 up
Общий стартовый скрипт почти не поменялся, для сокращения его объёма при имеющихся количестве хостов я решил сделать отдельный каталог с файлами-скриптами по именам хостов для их персональных настроек. Такой скрипт для хоста Br /etc/hostnames/br вызывается после общего скрипа конфигурирования мостов:
#!/bin/sh
echo Set route for test
route add -net cr-net/24 dev br0
# set tap6
arp -s corp-gw ${a}6
route add -host corp-gw1 gw corp-gw dev br0
ebtables -t nat -A PREROUTING -p ARP -i eth2 --arp-op Request --arp-ip-dst `resolv corp-gw` -j arpreply --arpreply-mac ${a}6
echo Set SNAT/DNAT
iptables -t nat -A POSTROUTING -s $HOSTNAME -d corp-gw1 -j SNAT --to-source `resolv cr-gw`
iptables -t nat -A POSTROUTING -s users -o eth0 -j SNAT --to-source `resolv $HOSTNAME`
iptables -t nat -A PREROUTING -d br -p tcp --dport 8080 -j DNAT --to-destination `resolv users`:80
/etc/tun.sh server inet/24 br -A cr-gw -B inet-net -r /etc/tun.sh
nohup /etc/sw.sh < /dev/null > /dev/null 2> /dev/null &
Разберем его построчно. Первая строка route вручную добавляет маршрут к зеленой сети, по которой осуществляется обмен по мосту этого хоста. Как уже говорилось, у этого моста и его интерфейсов адресов нет, ядро не будет добавлять этот маршрут автоматически. Далее мы уже можем указывать маршруты для удаленных сетей через шлюз находящейся в только что добавленной сети. Но без указания MAC обмен всё равно не пойдёт, так что добавим следующей строкой статическую запись результата протокола ARP. Строку ebtables мы уже отдельно разобрали в главе "И опять о ebtables...". Далее устанавливаем трансляции сетевых адресов:
#!/bin/sh PORT=5500 KEY_FILE="/etc/key_tun.txt" cmd=$1 if [ x == "x$cmd" ]; then if [ -n "$TUN_DEV" ]; then logger "VU4TUN: route add -net cr1-net/24 dev $TUN_DEV" route add -net cr1-net/24 dev "$TUN_DEV" exit 0 fi echo "Usage $0 server/client or set $TUN_DEV" >&2 exit 1 fi shift LOCAL=$1 shift R_B=$1 shift if [ "x$cmd" == xclient ]; then echo Configure VU4TUN as client vu4tun -p -l "$LOCAL" "$@" -k "$KEY_FILE" "$R_B" $PORT elif [ "x$cmd" == xserver ]; then echo Configure VU4TUN as server vu4tun -p -l "$LOCAL" "$@" -k "$KEY_FILE" -b "$R_B" $PORT fi
Свою программу по установлению туннеля я обозвал как vu4tun. Она поддерживает аутентификацию обеих сторон одним паролем по принципу chap-md5. Если первый аргумент не server и не client, то проверяем переменную $TUN_DEV и добавляем маршрут до удаленной стороны через туннель. В нашей лаборатории это делает только сторона Br, где все маршруты сразу присутсвуют и работает по умолчанию мост, поэтому маршрут у нас захаркожен для сети cr1-net. В зависимости от режима ($1) мы указываем: для клиента $2 — адрес сервера, а для сервера $2 — адрес, на который сервер должен сделать bind (опция -b), остальные аргументы (сети для передачи по туннелю) передаются программе напрямую ("$@")
Скрипт-переключатель основной-запасной имеет 4 состояния: начальное (state=0), когда все настройки проделаны внешними скриптами по установке маршрутов и броутинга для работы по основному каналу. В цикле проверяем доступность удаленной стороны по основному каналу. Если state пока 0 и появились проблемы прохождения ping с желаемым MTU и запрещенной фрагментацией (-M do — включаем режим определения mtu путем установки DF), то однократно для изменения state 0 в 1 сообщаем в лог о проблеме. Только после того, как мы убедились, что основной канал не работает, производится проверка запасного канала. Если он так же не работает, то меняем state на 2 и сообщаем о проблемах в лог и об этом. Если же запасной канал работоспособен, то меняем статус на 3 если он еще пока не равен 3 и только тогда производим переключение на запасной канал и производим информирование в лог об этом. Если основной канал заработал, то есть в новой итерации цикла проверка основного канала стала удачной и статус был равен 3, то переключаем на основной канал и меняем статус на начальный — 0.
#!/bin/sh MAIN=corp-gw1 REZ=r1 state=0 logger "switcher started" while true; do if ! ping -c1 -M do -s 1456 $MAIN > /dev/null 2>&1 ; then if [ $state -eq 0 ]; then logger "Can not ping MAIN ($MAIN)" state=1 fi if ! ping -c1 -M do -s 1456 $REZ > /dev/null 2>&1 ; then if [ $state -eq 1 ]; then logger "Can not ping REZERV ($REZ)" state=2 fi else if [ $state -ne 3 ]; then logger "Change the corporative channel to REZERV" /etc/brouting.sh eth2 state=3 fi fi elif [ $state -eq 3 ]; then logger "Change the corporative channel to MAIN" /etc/brouting.sh state=0 fi sleep 1 done
Как и в прошлой статье, все настройки в прилагаемом едином образе виртуальных машин уже проделаны для успешного прохождения тестов. Небольшое исключение есть в том, что "облако 4G" не сконфигурено и это надо делать самостоятельно. В ядре добавлена поддержка трансляции ARP, моя версия busybox уже включает все необходимые утилиты, в том числе полноценные утилиты ping, ip, iptables, ebtables и мою программу установки туннеля. Логгинг в моих настройках лаборатории выводит свои сообщения на 6-й терминал. Сильно уменьшая mtu, а потом восстанавливая на интерфейсах ext-ext1 можно увидеть как появляются сообщения о переключении каналов. Особенность конфигурации в том, что маршрутизация будет асимметричной при изменении mtu не на ext/ext1, а только на одной стороне copr-gw или copr-gw1. Как и в прошлой статье проверять имя исходящего и получившего соединение хоста можно тривиальным тестовым CGI-скриптом, который запрашивает мой http-сервер из busybox с URL http://remote/cgi-bin/test.cgi показывает свой HOSTNAME так и REMOTE_ADDRESS. Скрипт: /bin/www.sh хост [порт]
Так для пользователей Интернета центрального офиса все обращения к "Интернету", а именно к интерфейсам с белыми (жёлтыми) адресами этот скрипт в качестве REMOTE_ADDRESS должен показать "br" — адрес подмены, для филиала — с хоста corp-gw1, который у нас выполняет также роль пользователя Интернет — igw1.
Проверка работоспособности доступа в Интернет от хоста corp-gw1 интересна ещё и тем, что мы доказываем, что воровство IP для установки туннеля не помешала маршрутизатору использовать "белый" IP. Важно помнить, что в этой статье межсетевой экран не рассматривается и не конфигурируется, все хосты доступны друг другу, если сконфигурены шлюзы, поэтому стоит обращать внимание не только на возможность соединения, но и на оба адреса, локальный и удаленный.
Если вы хотите убедиться, что без трансляции ARP основной канал не работает, необходимо не только отключить эту трансляцию, поменяв в вызове ebtables опцию -A на опцию -D, но и очистить ядерные таблицы ARP, записи в которые были помещены как нами вызовом arp -s, так и самим ядром, вызвав arp -d хост.
Переконфигурация виртуального образа после изменения изнутри путем перезагрузки можно проводить командой /etc/mkres -r Стоит помнить, что если вы начали после этого править другую запущенную машину, то конфиг на ней пока будет без изменения, и если вы хотите получить содержимое уже после изменения на первой машине, то стоит перезапустить и эту машину, но уже командой reboot и только после перезагрузки первой машины, чтобы была гарантия, что образ с первыми изменениями уже полностью перезаписан.