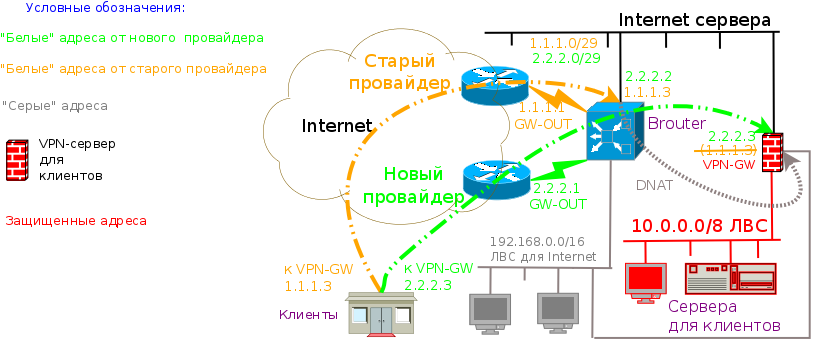
Настал ожидаемый момент перехода с одного провайдера назад к первому, что был у нас ещё со времен царя Гороха. Правда теперь вернуть целую сеть/24 не удастся, так что экономия адресов и центральный маршрутизатор-брандмауэр остается в силе. Временно все серверы получили либо по второму "белому" IP адресу, либо принято решение старые адреса перенести на центральный маршрутизатор, а сервис предоставлять путем DNAT на новые адреса серверов. Так как клиентов у нас не занимать, то информирование и собственно перенастройка у них осуществляется постепенно, то есть соединяются они как к старым так и новым адресам.
Настройка центрального шлюза теперь следующая: от шлюзов провайдеров патчкордами создано непосредственное соединение в разные эзернет-порты броутера, эти оба порта объедененны в мост, куда также добавлен порт с коммутатора сети белых адресов. Тем самым мы не фильтуем исходящий трафик, а вот входящий, невзирая на единую эзернет сеть не только фильтруется в одном месте, но и осуществляется вся маршрутизация, включая multihome специфику и NAT. Сеть "серых" адресов ничего особенного не представляет, там работают рабочие места ЛВС Интернет посредством SNAT в новый адрес броутера, который установлен на нём в качестве интерфейса к маршрутизатору нового провайдера по умолчанию.
Удивительно, но готовый рецепт такой связки: мост, DNAT и два провайдера я, сколько не гуглил, так и не нашёл. Впрочем, оказалось, что мост имеет свою специфику, но она тоже отдельная и на NAT напрямую не влияет. Хотя с мостом оказалось ещё и другая засада: отладив все на тестовом стенде при переносе на рабочую машину оказалось, что оно не работает по причине изменения алгоритмов взаимодействия iptables и мостов в новых 4.4 ядрах Linux по сравнению с 3.10.
Итак. Классический DNAT для экономии публичного адреса, путем пересылки сервиса к серверу на непубличный IP (у нас VPN на UDP):
PUB_IP=2.2.2.3 VPN_LOC_IP=192.168.1.3 VPN_PORT=4433 iptables -t nat -A PREROUTING -p udp -d $PUB_IP --dport $VPN_PORT -j DNAT --to-destination $VPN_LOC_IP:$VPN_PORT
С этим правилом нет никаких проблем. Новая сеть на интерфейсе с маршрутизатором по умолчанию, "серая сеть" — не в мосте. Обратные пакеты идут снова на наш центральный маршрутизатор и по запомненному соединению (для UDP это когда возвратные порты меняются местами со входящими) ядро само автоматически делает SNAT, заменяя "серый" адрес на белый и отправляет на шлюз по умолчанию.
Попробуем теперь всё это проделать для старого адреса. Пойдём по простой схеме: заберём старый публичный адрес у VPN сервера и сведем задачу к предыдущей:
OLD_PUB_IP=1.1.1.3 iptables -t nat -A PREROUTING -p udp -d $OLD_PUB_IP --dport $VPN_PORT -j DNAT --to-destination $VPN_LOC_IP:$VPN_PORT
Да, оно не работает. Посмотрим на анализатор трафика. К нам на входной мост пришли пакеты на старый IP, мы его успешно перенаправили на наш сервер. Возвратные пакеты проходя через наш броутер автоматически заменяются на правильный белый старый адрес, но уходят они к новому провайдеру, который такой асимметричный рутинг делать не хочет и его можно понять.
Ну так и что, скажете вы. Обычное дело. Надо сделать policy-routing и "рулить" между двумя шлюзами по умолчанию. Но об этом не было забыто и source-routing был уже мной включен:
echo 123 old_provider >> /etc/iproute2 ip route add default via $OLD_GW_OUT dev br0 table old_provider ip rule add from $OLD_PUB_IP lookup old_provider ip rule add from $OLD_PUB_IP2 lookup old_provider ... ip route flush cache
После этого все "белые" сервера продолжают работать на старых адресах, а вот NAT никак не хочет. Никакого переназначения на старый шлюз по умолчанию не происходит.
Если внимательно прочитать правило, которое ядро автоматически применит к обратным пакетам, то стоит обратить внимание на "POSTROUTING":
iptables -t nat -A POSTROUTING -p udp -s $VPN_LOC_IP --sport $VPN_PORT -j SNAT --to-source $OLD_PUB_IP:$VPN_PORT
То есть ядро меняет src-адреса уже после роутинга, то есть после того, когда исходящий интерфейс уже выбран! А это означает, что вначале ядро выберет исходящий интерфейс по имеющимся обратным пакетам с локальным адресом сервера и внешним к нам адресом клиента. Так как адрес у нас локальный, то policy правила не применятся, а сработает правило по умолчанию для маршрутизации по внешним к нам адресам.
Если внимательно погуглить дальше, то можно найти подходящее решение. Необходимо промаркировать пакеты так, чтобы выбор исходящего интерфейса происходил не автоматически перед SNAT, а по маркерам на пакетах. Ситуация осложняется тем, что мы отправляем пакеты на сервер, который, конечно, не увидит эти локальные пометки на пакетах и потому они придут от сервера уже без пометок. Поэтому надо ещё задействовать сохранение меток, для этого служит комплексный механиз "CONNMARK" — запомнить пометку на соединении. На возвратных пакетах мы восстанавливаем метку. Но как бы не так! Если мы сделаем правила рутинга по отправке промаркированных пакетов, то рутинг перенаправит вначале наши DNAT-пакеты, так как мы редиректим на другую сеть и туда надо отправить по рутингу.
После долгих размышлений и битв с анализатором пакетов, я придумал перемаркировку, или вообще целую программу в момент рутинга входящих и исходящих пакетов:
iptables -t mangle -A PREROUTING -d $OLD_PUB_IP -p udp --dport $VPN_PORT -j MARK --set-mark 1 iptables -t mangle -A PREROUTING -d $OLD_PUB_IP -p udp --dport $VPN_PORT -j CONNMARK --save-mark iptables -t mangle -A PREROUTING -s $VPN_LOC_IP -p udp --sport $VPN_PORT -j CONNMARK --restore-mark iptables -t mangle -A PREROUTING -m mark --mark 1 -s $VPN_LOC_IP -j MARK --set-mark 2
Почему mangle? Точка входа (хук) mangle PREROUTING расположена до точки nat PREROUTING и правила сработают в приведенном выше порядке до nat, впрочем mangle ещё и менее затратный механизм.

В конечном результате у нас будут возвратные пакеты c меткой 2, на которые уже можно сделать правило маршрутизации, которое, как уже описывалось, сработает до автоматического SNAT и потому интерфейс будет выбран соответствующий нашему желанию — правилу к нужному провайдеру.
ip rule add fwmark 2 table old_provider ip route flush cache
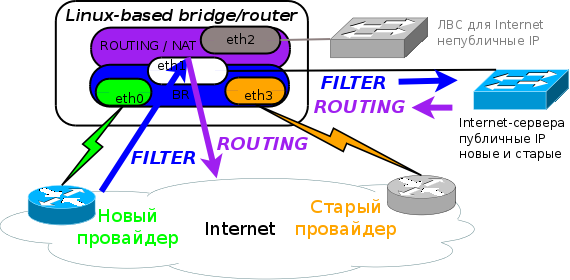
С одной стороны я рассматривал мой полумост, когда со стороны нашей сети нет моста, а есть маршрутизатор, потому все пакеты проходят через него и маршрутизируются между интерфейсами. Как следствие, нам не надо задумываться, что указывать в качестве интерфейсов в правилах NAT, они будут единственны в своём роде, если только провайдеры не договорятся пропускать выданные нам адреса друг друга.
С другой стороны, а именно со стороны провайдера, входящите пакеты будут проходить через мост и вот правила фильтрации для пакетов, проходящих мост на новых ядрах теперь имеют новые особенности.
Во-первых, чтобы пакеты прошли в механизм iptables из моста, для ядер 4+ надо дополнительно включить модуль br_netfilter и убедиться, что этот механизм не выключен:
modprobe br_netfilter echo 1 > /proc/sys/net/bridge/bridge-nf-call-iptables
Во-вторых, в правилах фильтрации необходимо указывать имена реальных интерфейсов, например, -m physdev --physdev-out eth1. Метод, когда старые и белые адреса находятся в одном эзернете имеет удобство в том, что для общих правил можно указывать именно исходящие в этот интерфейс, и одно правило будет срабатывать по старым и новым адресам. Для примера, начальные правила для ICMP у типичного брадмауэра:
A_FW_ETH1="-A FORWARD -m physdev --physdev-out eth1" $IPTABLES $A_FW_ETH1 -p ICMP --icmp-type 3 -j ACCEPT # Destination Unreachable $IPTABLES $A_FW_ETH1 -p ICMP --icmp-type 4 -j ACCEPT # Source Quench $IPTABLES $A_FW_ETH1 -p ICMP --icmp-type 8 -j ACCEPT $IPTABLES $A_FW_ETH1 -p ICMP --icmp-type 11 -j ACCEPT # Time Exceeded $IPTABLES $A_FW_ETH1 -p ICMP --icmp-type 12 -j ACCEPT # Parameter Problem $IPTABLES $A_FW_ETH1 -p ICMP --icmp-type 0 -j ACCEPT # echo $IPTABLES $A_FW_ETH1 -p ICMP -j DROP # other
Не стоит смущаться, что используется таблица FORWARD, на самом деле все правила для моста так и надо назначать при проходении моста, то есть пересылки с одного интерфейса моста в другой.

Впрочем, новое ядро (или iptables?) при установке таких правил всё равно будет спамить в syslog по нескольку таких вот строк на каждое правило:
xt_physdev: using --physdev-out in the OUTPUT, FORWARD and POSTROUTING chains for non-bridged traffic is not supported anymore.
На самом деле у наших криптошлюзов есть обидный дефект. В независимости от назначенных маршрутов при установке нескольких внешних адресов, исходящие пакеты отправляются с интерфейса шлюза по умолчанию. Именно исправление этого дефекта и побудило начать многочисленные эксперименты на тестовом стенде, где и родилась методика двойной маркировки пакетов и там все заработало. Вот результат:
iptables $FW_ETH1 -d $NEW_IP -p udp --dport $VPN_PORT -j MARK --set-mark 3 iptables $FW_ETH1 -d $NEW_IP -p udp --dport $VPN_PORT -j CONNMARK --save-mark iptables -t mangle -A PREROUTING -s $NEW_IP -p udp --sport $VPN_PORT -j CONNMARK --restore-mark iptables -t mangle -A PREROUTING -m mark --mark 0 -s $NEW_IP -p udp --sport $VPN_PORT -j MARK --set-mark 4 iptables -t nat -A POSTROUTING -m udp -p udp --sport $VPN_PORT -m mark --mark 4 -j SNAT --to-source $OLD_IP:$VPN_PORT
Логика такая:
Вроде бы всё хорошо. И даже оно работало. На ядре 3.10. А вот на ядре 4.4 последнее правило ничего не делает. Нет, всё что выше до него и оно само готово для срабатывания, это легко на самом деле "починить", достаточно убрать :$VPN_PORT у --to-source. В результате мы получим PAT, который бы годился для TCP, но для UDP динамические порты в качестве исходных не годятся, а вот с указанием порта правило просто молча перестаёт работать на 4.4! Буду благодарен за помощь в разъяснении последней засады.